Quick Tip For Working With Mechanize
The other day I came up with the great idea of publicly shaming myself if I didn’t make it to the gym in the past x days/weeks. It sounds rather twisted, but I’m in a good spot right now with my eating and fitness and I don’t want that to slip away. Being a developer, I thought this could be fun and relatively easy to do given easy access to a portal on my gym’s website that includes attendance records.
Sounds like a good opportunity to work with Mechanize! I quickly found that my gym’s portal wasn’t as easy to parse using Mechanize as the examples used in the documentation. I found using the search method to look for the XPath of the elements I’m looking for would work well. With Chrome(and I assume other browsers), it’s rather simple to get the XPath of an element.
I’ll use the Google homepage as an example since my gym’s page is a bit more cluttered.
If you right click on an element of the page you want to find and inspect it. (I’m trying to find the Google Search button for some reason)
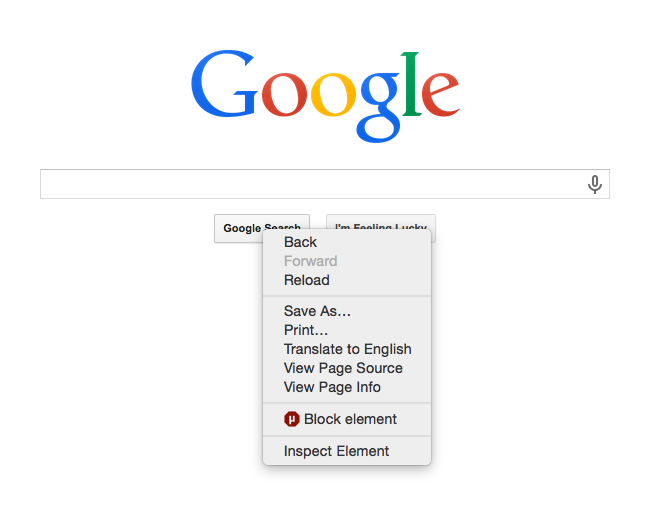
This will open up the DevTools window and highlight the element you’re looking for in the Elements tab. Now, if you right click the highlighted element, you’ll see an option to copy Copy XPath.
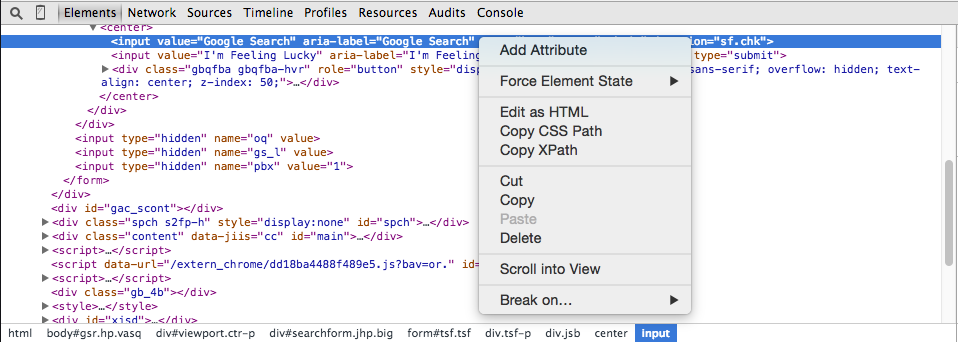
With the XPath copied you can use it in your search:
agent.get('http://google.com').search("//*[@id='tsf']/div[2]/div[3]/center/input[1]")Hope this helps anyone in need of a quick way to find elements on a page using Mechanize. It’s worth noting that for pages that have a much simpler structure (like our example) it’ll be best to use the other methods of finding and interacting with elements on the page available in the documentation.